Berka Dataset Pipeline
Analyse de données bancaires du Berka Dataset (1993-1998) pour calculer et visualiser des KPI clés
ETLData PipelineBanking AnalyticsDashboard
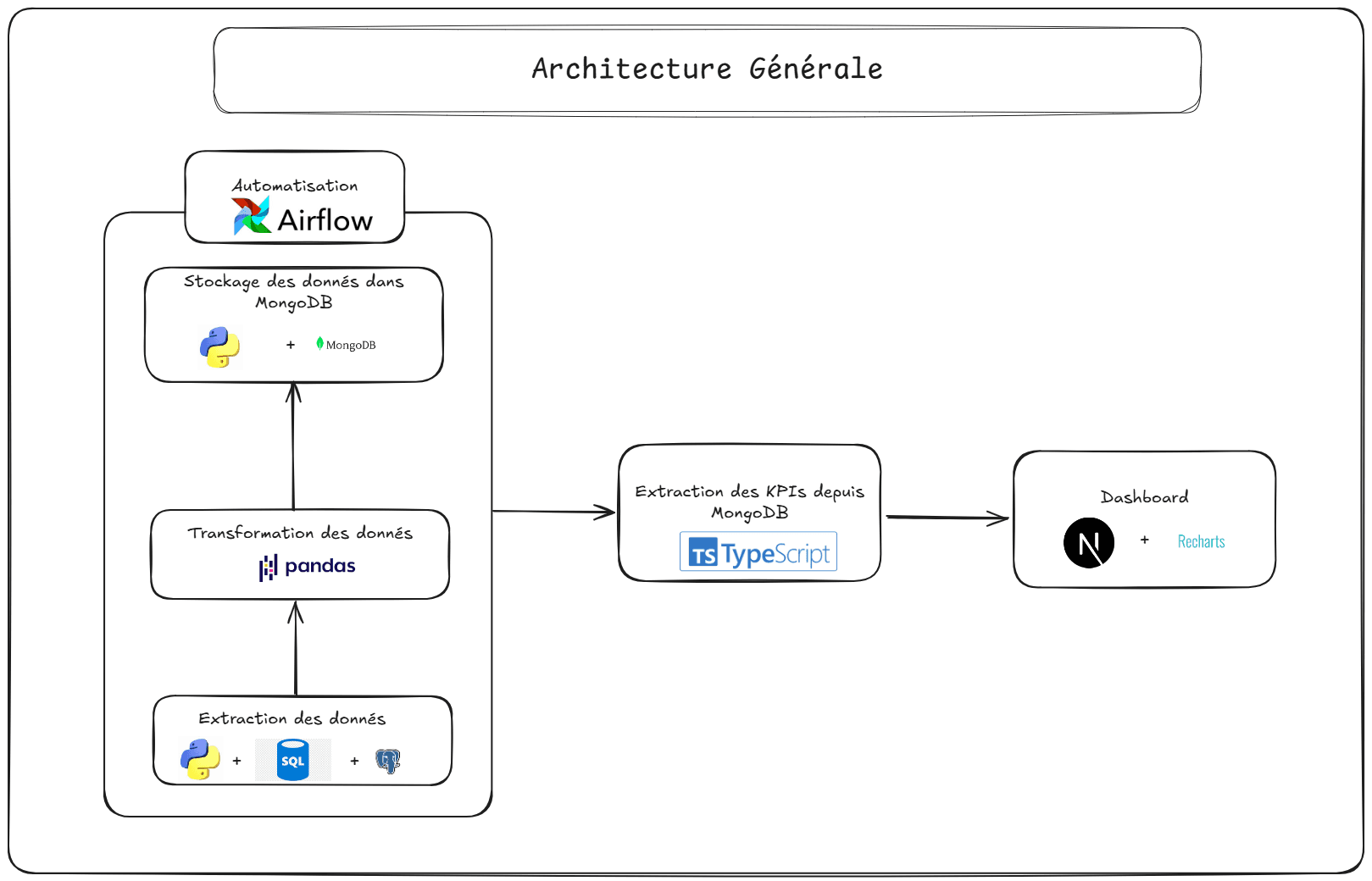
Flux de données
1. Extraction
Chargement des données brutes du Berka Dataset (CSV) dans une base PostgreSQL (Neon) avec Python, suivi d'une extraction vers des fichiers CSV.
PostgreSQLPythonpandasSQLAlchemy
2. Transformation
Nettoyage et normalisation des données, puis calcul des KPI (volume, statuts des prêts) avec Python (`pandas`, `plotly`). Automatisation quotidienne via Airflow.
PythonpandasplotlyAirflow
3. Chargement
Sauvegarde des KPI dans MongoDB Atlas (NoSQL) avec Python (`pymongo`).
MongoDB Atlaspymongo
4. Visualisation
Extraction des KPI depuis MongoDB (avec fallback CSV) et affichage dans un dashboard Next.js utilisant TypeScript, Tailwind CSS, et `recharts.js`. Déploiement sur Vercel.
Next.jsTypeScriptTailwind CSSrecharts.jsVercel
5. Monitoring
Validation des KPI et monitoring du pipeline avec Airflow logs.
Airflow